프로세스란 종단 시스템, 즉 어플리케이션 계층에서 실행되는 프로그램을 의미한다.
그럼 프로세스 간의 통신은 언제 일어날까?
먼저 통신 프로세스가 동일한 어플리케이션 계층에서 실행될 때 발생한다.
같은 계층 안에서 프로세스간에 이루어지는 통신은 어플리케이션 계층, 즉 종단 시스템의 운영체제에 따라 그 방식이 결정된다.
두번째로 서로 다른 어플리케이션 계층 간에도 프로세스 통신이 발생할 수 있다.
서로 다른 2개의 종단 시스템에서 프로세스는 컴퓨터 네트워크를 통해 메시지(message)를 교환하는 방식으로 통신한다.
송신 프로세스가 메시지를 만들어 네트워크로 보내면, 수신 프로세스는 메시지를 받아 다시 그에 대한 응답 메시지를 보내는 식이다.
네트워크 통신에서 프로세스 간 통신이라 하면, 주로 이렇게 서로 다른 어플리케이션 계층 간의 통신을 의미한다.
이번 포스팅에서는 네트워크 통신에서의 프로세스 간 통신에 대해 알아보자.
클라이언트 프로세스 & 서버 프로세스

이전 포스팅에서 클라이언트 - 서버 어플리케이션 구조에서는 클라이언트끼리 직접적으로 통신하는 것이 아니라, 서버가 클라이언트와
클라이언트 사이에서 중재자 역할을 하며, 클라이언트가 보낸 데이터를 다시 다른 클라이언트에게 전달해 준다는 내용을 살펴보았다.
이 때 클라이언트가 바로 클라이언트 프로세스를 의미하고, 서버가 서버 프로세스를 의미하며,
클라이언트와 서버 사이를 왔다갔다 하는 데이터가 바로 메시지를 의미한다고 이야기할 수 있다.
즉 클라이언트 브라우저 프로세스가 웹 서버 프로세스와 메시지를 교환하는 경우,
브라우저는 클라이언트 프로세스이고, 웹 서버는 서버 프로세스인 것이다.

P2P 구조에서 피어(peer) 역시 하나의 프로세스라고 할 수 있는데, 이 때 피어는 클라이언트 프로세스가 될 수도 있고,
동시에 서버 프로세스가 될 수도 있다.
이런 경우 클라이언트 프로세스와 서버 프로세스는 다음과 같이 분리된 개념으로 보면 편하다.
• 클라이언트 프로세스 : 두 프로세스 간의 통신 세션에서 통신을 초기화하는 프로세스
(다른 프로세스와 세션을 시직하기 위해 접속을 초기화 시킴)
• 서버 프로세스 : 세션을 시작하기 위해 접속을 기다리는 프로세스
웹 브라우저는 웹 서버와 접촉을 초기화한다.
따라서 브라우저 프로세스는 클라이언트 프로세스이고, 웹 서버 프로세스는 서버 프로세스이다.
P2P 파일 공유 어플리케이션에 피어 A, B 가 있다고 가정하자.
A 가 B 에게 특정 파일을 보낼 것을 요청하는 경우 A 는 클라이언트 프로세스, B 는 서버 프로세스이다.
반대로 B 가 A 에게 특정 파일을 보낼 것을 요청하는 경우 다시 B 가 클라이언트 프로세스, A 가 서버 프로세스가 된다.
쉽게 말해 요청을 보내는 쪽이 클라이언트, 요청을 받고 응답을 보내주는 쪽이 서버이다.
소켓 between 프로세스 & 컴퓨터 네트워크

대부분의 어플리케이션은 메시지를 주고 받는 두 통신 프로세스의 쌍으로 구성된다.
이 때 두 프로세스간의 메시지는 인터넷, 즉 네트워크를 통해 움직이며, 프로세스는 소켓(socket)을 통해 네트워크로 메시지를 보내거나 받는다.
쉽게 말해 프로세스는 집 이고 소켓은 출입구이며, 메시지는 출입구를 통해 집을 빠져 나간다고 볼 수 있다.
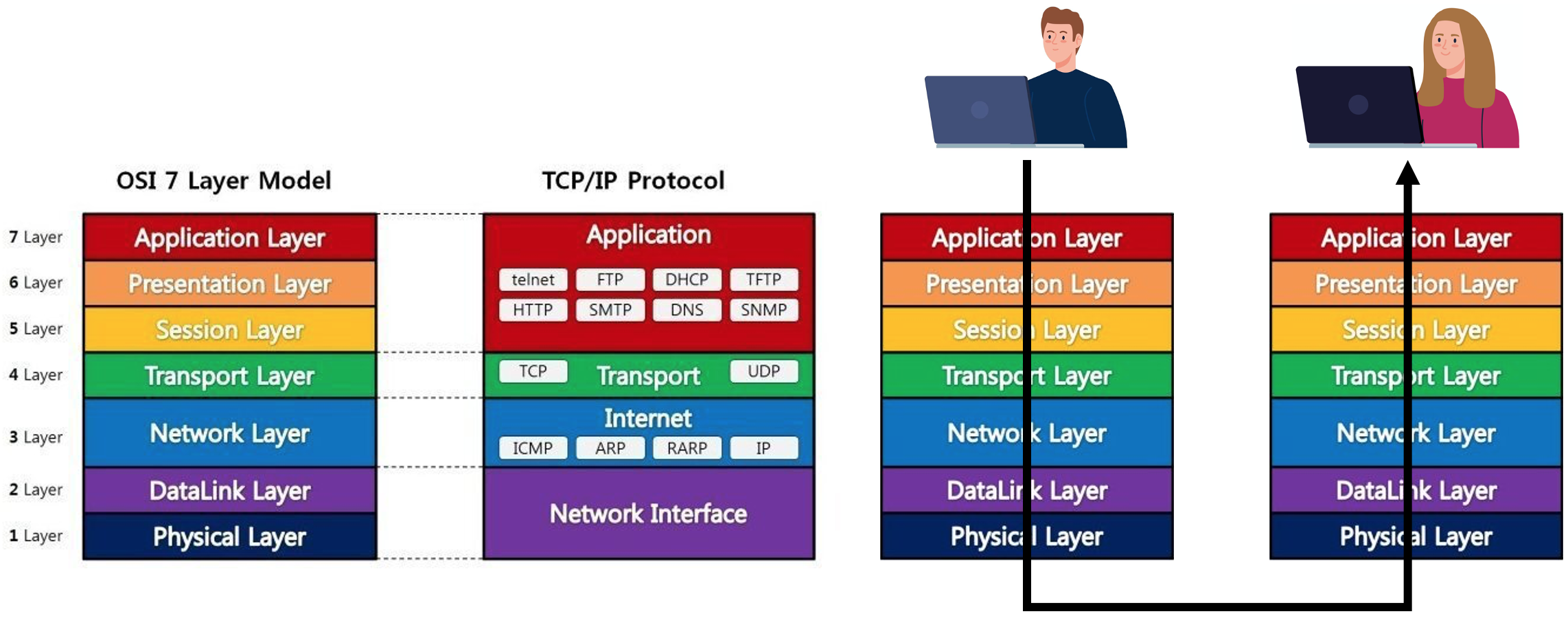
지난 포스팅에서 살펴본 OSI 7 계층을 떠올려 본다면,
소켓은 어플리케이션 계층과 트랜스포트 계층 간의 인터페이스 이며, API 라고 이야기할 수도 있다.
이 때 어플리케이션 개발자는 어플리케이션 계층에 대해서는 모든 통제권을 가지나, 트랜스포트 계층에 대해서는 그렇지 않다.
트랜스포트 계층에 대해 어플리케이션 개발자가 조작할 수 있는 것은 트랜스포트 프로토콜을 선택하는 것과,
최대 버퍼/세그먼트 크기 등의 매개변수를 설정하는 것 뿐이다.
어플리케이션은 개발자가 선택한 트랜스포트 프로토콜이 제공하는 전송 서비스를 사용하여 구성되는데,
이 트랜스포트 프로토콜에 대해서는 이후 포스팅에서 좀 더 자세히 알아보도록 하자.
프로세스 주소 : IP 주소와 포트 넘버
이전 포스팅에서 클라이언트-서버 구조를 다룰 때 고정 IP 주소의 개념을 간단하게 살펴본 적이 있었다.
프로세스간에 메시지를 주고 받기 위해서는 두가지 정보가 필요한데, 그 중 하나가 IP 주소이고,
나머지 하나는 IP 주소가 가리키는 목적지 호스트 안에서 통신에 참여하고 있는 프로세스의 식별자이다.
호스트 안에 여러개의 프로세스가 존재할 수 있기 때문에, 그 중 어떤 프로세스가 메시지를 보냈는지 알기 위해 식별자가 필요하고
포트 넘버(port number)가 바로 이 프로세스를 식별하는데 사용된다.
자주 사용되는 어플리케이션에는 보통 약속처럼 정해진 포트 넘버가 할당되는데,
예를 들어 웹 서버는 포트 넘버 80번으로 식별되고, SMTP 프로토콜을 사용하는 메일 서버는 포트 넘버 25번으로 식별된다.
인터넷 표준 프로토콜들이 이렇게 약속처럼 정해두고 사용하는 포트 번호 리스트는 여기에서 찾아볼 수 있다.
참고자료
컴퓨터 네트워킹 하향식 접근 - YES24
컴퓨터 네트워킹 하향식 접근
www.yes24.com
'CS Knowledge > Network' 카테고리의 다른 글
| [Network] 네트워크 어플리케이션 구조란? (0) | 2022.08.25 |
|---|---|
| [Network] OSI 7 계층이란? (0) | 2022.06.26 |
| [Server] 웹서버 vs WAS (0) | 2022.06.25 |
| [REST] REST API의 개념과 간단한 설계 원칙 (0) | 2022.05.06 |