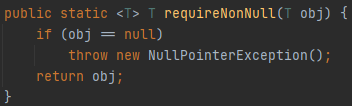
예외는 오직 예외 상황에만 사용할 것
예외를 제어 흐름용으로 사용하지 말자
• 예외는 오직 예외 상황에서만 사용해야 한다.
• 일반적인 제어 흐름용으로 사용해서는 안됨
◦ 코드를 헷갈리게 한다(코드가 직관적이지 못하다).
◦ 성능 저하의 원인이 될 수 있다.
◦ 엉뚱한 곳에서 발생한 버그를 숨겨버릴 수 있다.
예외를 제어 흐름용으로 사용한 예시
try {
int i = 0;
while(true) { mountainList[i++].climb(); }
} catch(ArrayIndexOutOfBoundsException e) {...}
for(Mountain m : mountainList) { m.climb(); }
• 두 코드 모두 mountainList 배열의 원소를 순회하는 목적으로 쓰여졌다.
• 예외를 제어흐름용으로 사용하니 코드가 전혀 직관적이지 못하다.
• 이 작자는 코드를 왜 이렇게 짰을까?
◦ JVM 은 배열에 접근할 때 마다 경계를 넘지 않는지 검사한다.
◦ for 문은 배열의 경계에 도달하면 반복문을 종료한다.
◦ for 문 안에서 배열에 접근하고 있으니, 배열의 경계에 대한 검사를 2번 하고 있다고 생각할 수 있다.

◦ 중복 검사를 피하면 성능을 향상시킬 수 있지 않을까? → 예외를 사용에 제어 흐름을 구현하면 되겠다!
◦ 이 추론이 잘못된 이유
- 예외는 예외 상황에 쓸 용도로 설계된 것이다. JVM 개발자가 최적화에 신경쓰지 않았을 가능성이 크다.
- 코드를 try-catch 블록 안에 넣으면 JVM 이 적용할 수 있는 최적화가 제한된다.
- 배열을 순회하는 for 문은 앞서 걱정한 중복 검사를 수행하지 않는다. JVM 이 알아서 최적화해주기 때문.
- 결과적으로 성능이 개선되지 않는다! (실제로 코드를 돌려보면 예외를 사용한 쪽이 2배 이상 느리다)
◦ 뿐만 아니라 반복문 안에 버그가 숨어 있다면 흐름 제어에 쓰인 예외가 이 버그를 숨겨 디버깅을 훨씬 어렵게 할 수 있다.
- 반복문의 몸체 내부에서 다른 배열을 사용하는 경우, 해당 배열에서 ArrayIndexOutOfBound 예외가 발생할 수 있다.
- 표준 관용구
- 예외처리 하지 않고 스택 추적 정보를 남긴 다음 해당 스레드를 종료시킨다.
- 예외를 사용한 반복문
- ArrayIndexOutOfBound 예외 발생 = 배열 순회 종료 라고 간주하고 있음
- 즉 실제 버그 상황에서 발생한 예외를 반복문 종료 상황으로 오해하고 넘어간다.
코드를 짤 때는 꼼수를 쓰지 말자
• 표준적이고 쉽게 이해되는 관용구를 사용하라
• 성능 개선을 목적으로 과하게 머리를 쓴 기법은 자제하라.
◦ 꼼수로 성능이 개선되더라도 자바 플랫폼은 꾸준히 업데이트 되기 때문에 상대적인 성능 우위는 오래가지 않는다.
◦ 반면 꼼수에 숨겨진 미묘한 버그와 어려워진 유지보수 문제는 계속된다.
상태 검사 메소드 / 옵셔널 / 특정 값
상태 의존적 메소드와 상태 검사 메소드
• 지금까지 살펴본 원칙은 API 설계 시에도 유의해야하는 부분이다.
• 특히 특정 상태에서만 호출할 수 있는 상태 의존적 메소드를 제공하는 클래스의 경우, 상태 검사 메소드를 함께 제공해 사용자가
예외 처리를 제어 흐름에 사용하지 않도록 해줘야 한다.
◦ 상태 의존적 메소드 예시 : Iterator 의 next
- Iterator 에 다음 원소가 있어야 next 메소드 호출이 가능하므로
◦ 상태 검사 메소드 예시 : Iterator 의 hasNext
- Iterator 에 다음 원소가 있는지 여부를 hasNext 메소드를 통해 검사할 수 있다.
for (Iterator<Foo> i = collection.iterator(); i.hasNext(); ) { Foo foo = i.next(); }
• 상태 검사 메소드 없이 상태 의존 메소드만 있었다면, 사용자는 아래와 같이 코드를 작성할 수 밖에 없을 것이다.
try {
Iterator<Foo> i = collection.iterator();
while(true) { Foo foo = i.next(); }
} catch (NoSuchElementException e) {...}
상태 검사 메소드 / 옵셔널 / 특정 값
• 상태 검사 메소드 대신 올바르지 않은 상태일 때 빈 옵셔널을 반환하거나, null 같이 사전에 정의해둔 특정 값을 반환하는 방법도 있다.
• 아래는 이 세가지 방식 중 하나를 선택하는 것에 대해 책에서 소개하는 지침이다.
◦ 옵셔널 혹은 특정 값을 반환하는 방식
- 외부 동기화 없이 여러 스레드가 동시에 접근할 수 있는 경우
- 외부 요인으로 상태가 변할 수 있는 경우
→ 상태 검사 메소드와 상태 의존적 메소드를 호출하는 사이에 객체의 상태가 변할 수 있기 때문
- 성능이 중요한 상황, 상태 검사 메서드가 상태 의존적 메서드의 작업 일부를 중복 수행하는 경우
◦ 상태 검사 메서드를 사용하는 방식
- 위의 상황을 제외한 다른 모든 경우
→ 가독성이 더 좋다 + 상태 검사 메서드 호출이 누락된 경우 상태 의존적 메소드가 이를 잡아주기 때문에 버그를 잡기 쉽다.
- 단, 특정 값은 검사하지 않고 지나쳐도 발견하기 어렵다는 단점이 있다.
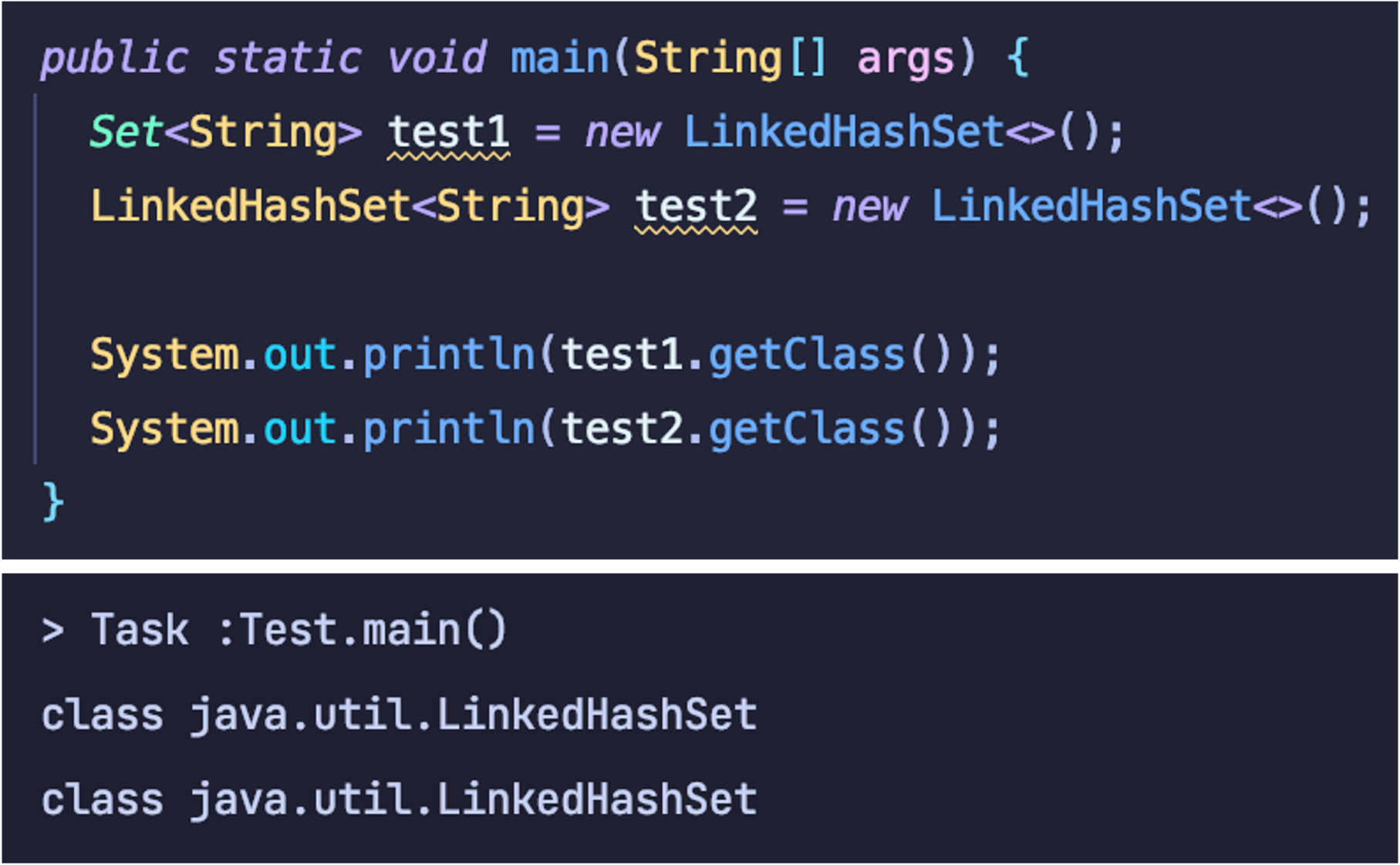
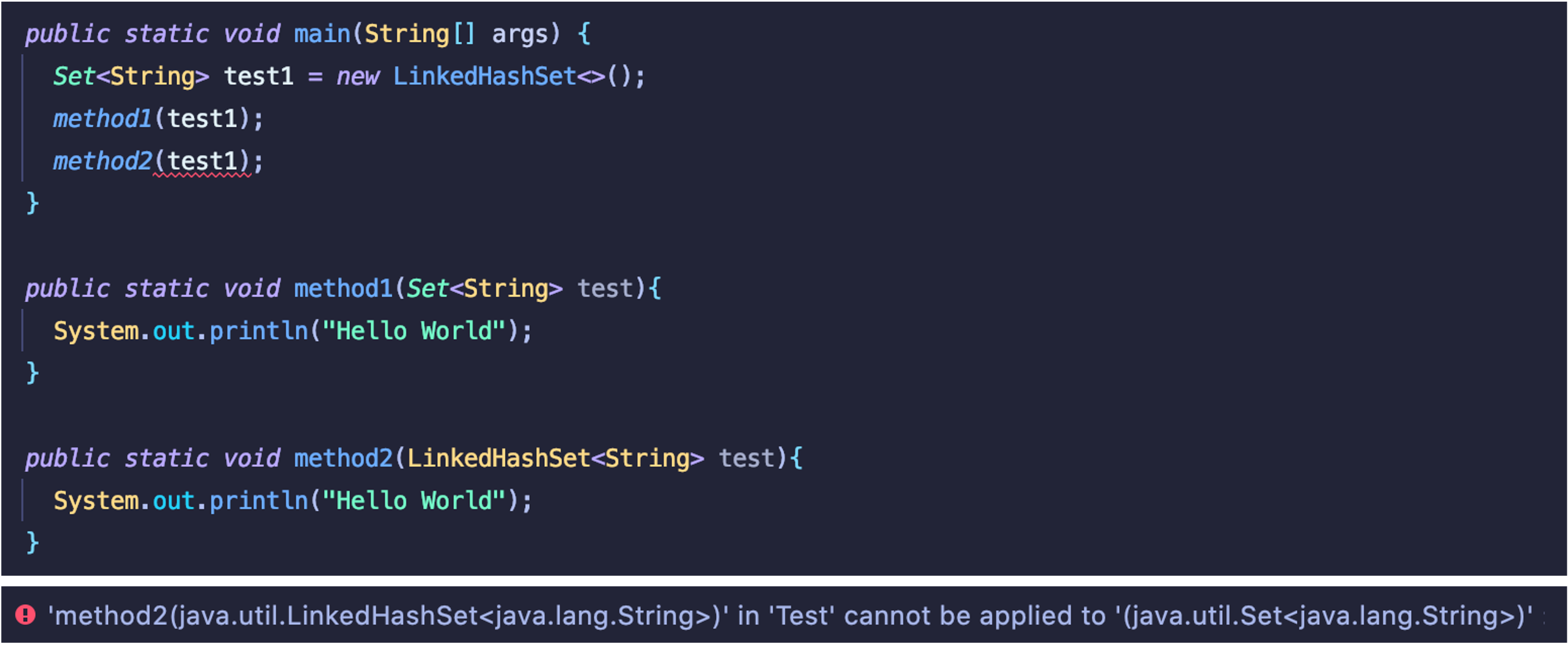
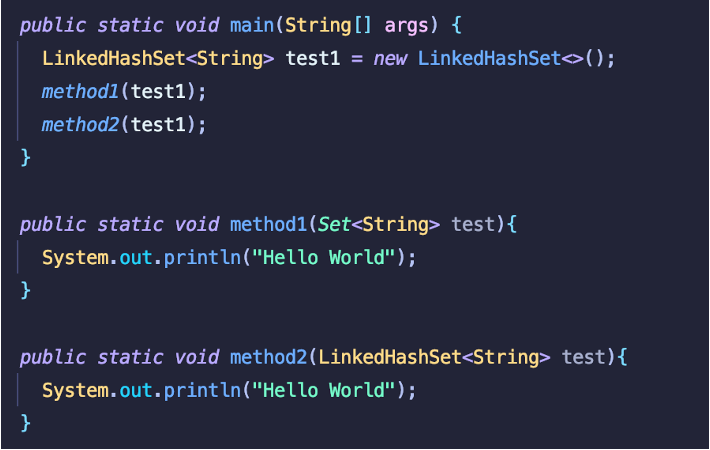
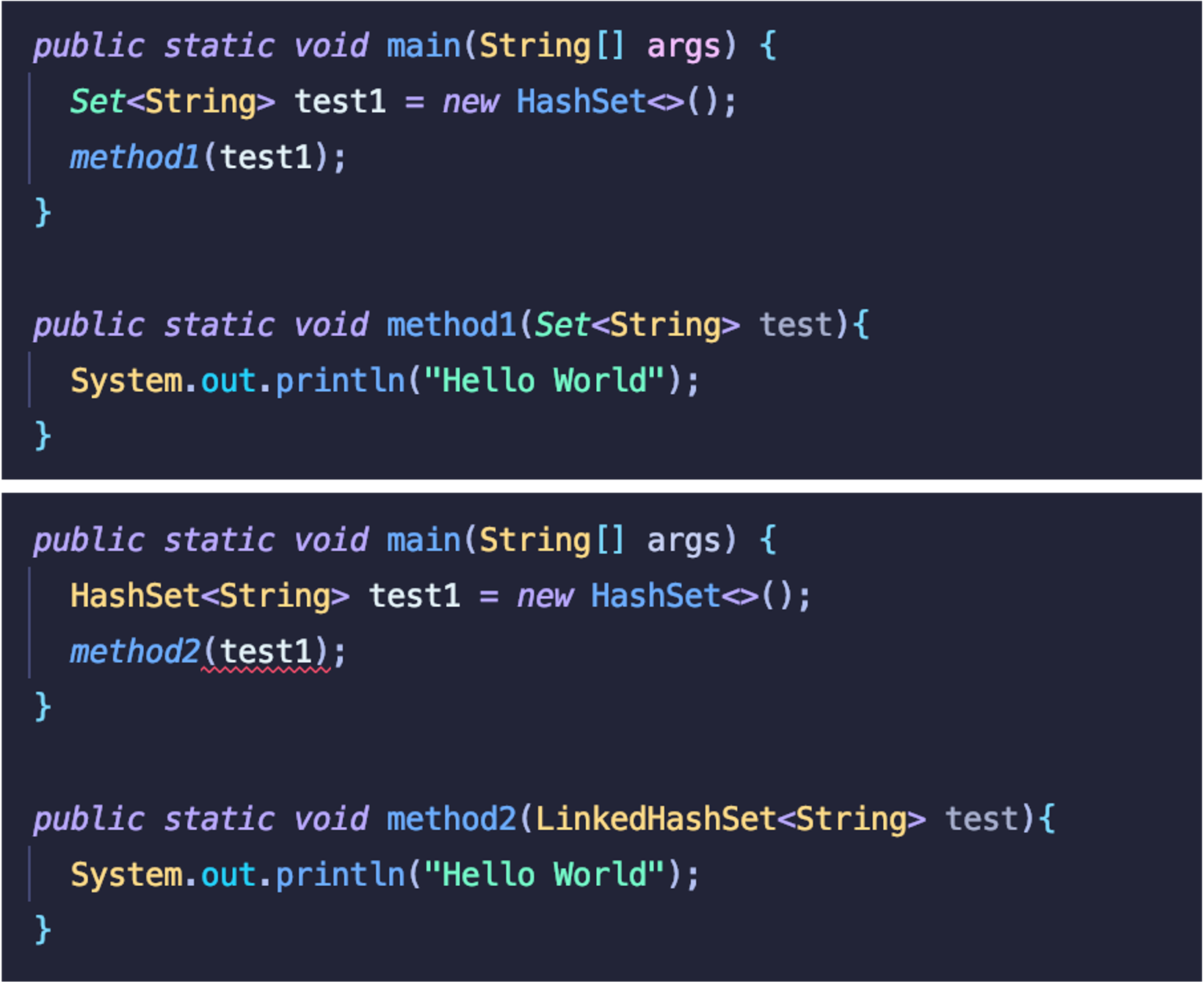
'Java' 카테고리의 다른 글
| [Effective Java] ITEM84 : 프로그램의 동작을 스레드 스케줄러에 기대지 말라 (0) | 2022.11.06 |
|---|---|
| [Effective Java] ITEM74 : 메서드가 던지는 모든 예외를 문서화하라 (0) | 2022.11.06 |
| [Effective Java] ITEM64 : 객체는 인터페이스를 사용해 참조하라 (0) | 2022.09.20 |
| [Effective Java] ITEM59 : 라이브러리를 익히고 사용하라 (0) | 2022.09.06 |
| [Effective Java] ITEM54 : null 이 아닌, 빈 컬렉션이나 배열을 반환하라 (0) | 2022.08.24 |